
From Distributed to Monolithic to Squeeze Your Resources

Importing 1.2 million contacts and 48 million emails every day to Gmail
At ShuttleCloud, a fast-growing start-up, our challenge has been to develop the most efficient platform architecture to import billions of messages or email contacts for our major customers, including Gmail, Comcast, and Time Warner Cable.ShuttleCloud moves more than 400 million contacts per year, close to 35 billion emails. This functionality is available to all Gmail users, a total of 900 million users. Having important clients means really demanding SLAs (Service-Level Agreements), up to 99.5% in some cases.Generic platformWhen we started working on this problem, we felt the best approach to tackle the data movement problem would be to have a generic platform capable of working with any kind of content. We also thought the platform should be distributed so that we could easily scale it according to our load, which is why our platform worked with hierarchical resources.If data could be described in terms of parents and children, it can be migrated. This approach works well and is certainly the right path to follow when you want to migrate anything, but it has drawbacks, and when you’re trying to not only migrate but also be the fastest migration service, then you can’t afford the trade-offs that you have with a generic solution.
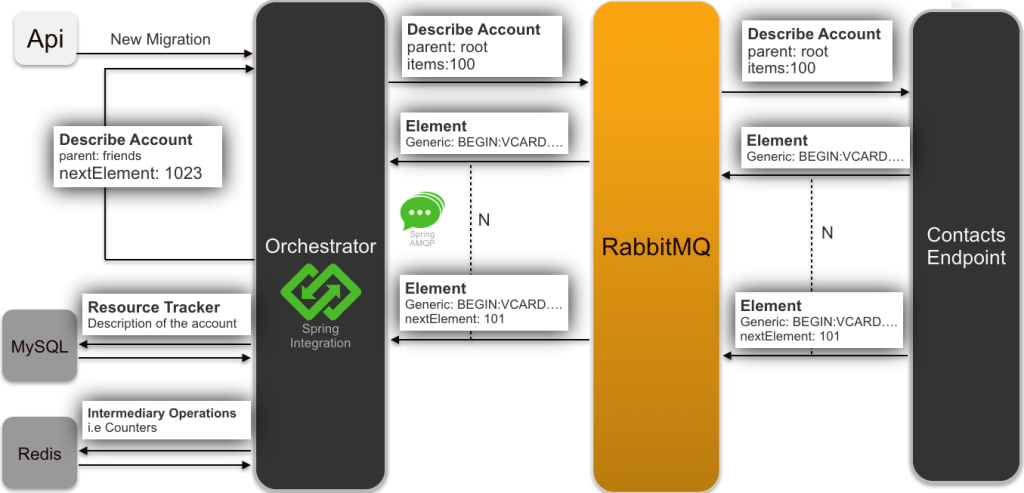
Old Platform Architecture
Key elements to change from a distributed system to monolithic
- Transport layer
Having a distributed platform means that every resource travels around the platform. When you’re migrating so many resources, a bottleneck can occur.
- Latencies
When a resource travels around your system, to calculate the total processing time, you should count not just the CPU and memory access time but also add some extra time coming out of network latencies, etc.
Most of the services also work with batches not only because of the speed but also because of API rate limits, which means that your endpoints need to wait for a number of resources before pushing them to the final destination, for example, 100. You need to be very careful in choosing this figure. It should be close to the average size of an account, which isn’t easy to have when your platform is generic, and it can migrate different kinds of resources.
If this figure is not perfect, your endpoints can spend more time waiting to complete the batch than working. Of course you can have time-outs, but that just mitigates the wait.
- Security
Moving user data around is usually a bad idea. The more places the data can be found, the easier it can be stolen, and cleaning becomes more difficult as well as ensuring there is no leak.
From generic to specific
Our architecture is distributed but not the migration platform. During a migration, data movement occurs between two processes inside the same instance; the data is shared only through memory.
In this way, we take the most of each instance, which is also one of the great advantages of this approach in that we have mini platforms that perform very well. Testing is easy, and it is also easy to detect problems and easy to scale. We have several pools of instances:
- Email migration: instances that know how to do email migration. Each instance can do 70 email migrations at the same time.
- Contact migration: instances that know how to do contact migration. Each instance can do more than 40 migrations at the same time.
After four years, we haven’t had any downtimes, and every day we do more than 16,000 migrations between email, contacts, and recurrence migrations (forwarding).
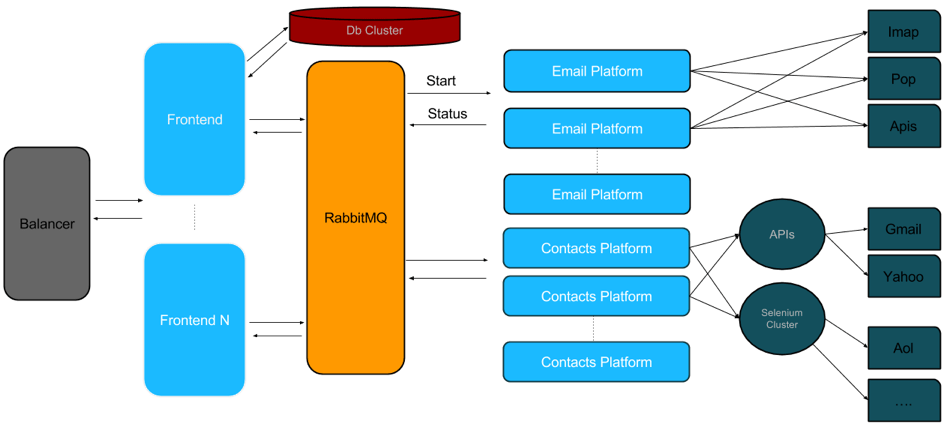
New Contacts Platform
The result:
- More than 11 migrations every minute.
- On average every contact account has 185 contacts, so we move around 1,200,000 contacts every day--more than 400 million contacts each year. Growth hacking you say? :D
- In two years, we’ve moved more than 2 billion contacts.
- On average we perform a contact migration every 11 seconds.
- An email account has on average 8,000 emails, so every day we move more than 48,000,000 emails--more than 35 billion emails each year.
- We support more than 242 email providers.
- We move 1TB of data every 6 hours, more than 220 TB/month.
You can see in detail how the platform functions in this talked I gave last year in the Spring One Conference, or you can see it in action at the Settings section of your Gmail account (through the Accounts and Import tab) or following this link: Gmail import email and contacts service.